Difference between revisions of "GlueX Offline Meeting, February 22, 2012"
(→EventStore) |
(→Reconstruction Output Format) |
||
| Line 62: | Line 62: | ||
==Reconstruction Output Format== | ==Reconstruction Output Format== | ||
| − | DST format | + | We talked about the UConn DST format. Mark (echoing Matt's comment at the last meeting) proposed that we support it as a collaboration and use it as a starting point for a reconstruction output format. It exists, it has been reviewed at some level by the collaboration, and had been designed with compactness in mind. |
| − | analysis should take place with | + | Matt reiterated his concept that analysis should take place with high-level objects in JANA. As such the DST should contain the minimum amount of information needed to recreate all the necessary objects. Some computation may be required to do this. It is therefore not necessary for there to be a one-to-one correspondence between elements in the DST event structure and the structure of the high-level analysis objects, although that is not excluded where appropriate. |
| − | + | Mark wondered whether the current DST could support this vision as it was not designed with this role in mind. Matt did not see any evidence that it could not. He thought we should focus our design effort on the structure of the analysis objects. If necessary, the DST and the lower-level objects could be reworked to support them; some tweaking and iteration will be necessary. | |
| − | + | We agreed to proceed this way along these lines and adopt the UConn DST as an initial serialization format. | |
| − | + | We talked briefly about making utilities to make say ROOT trees from DST's. Matt thought rather that it would be better to create the root trees from analysis objects, using the DST's to provide data to create said objects. | |
| − | + | ||
| − | + | ||
| − | + | ||
| − | We talked about | + | |
| − | Matt | + | |
==[https://mailman.jlab.org/pipermail/halld-offline/2012-February/000859.html EventStore]== | ==[https://mailman.jlab.org/pipermail/halld-offline/2012-February/000859.html EventStore]== | ||
Revision as of 16:30, 23 February 2012
GlueX Offline Software Meeting
Wednesday, February 22, 2012
1:30 pm EST
JLab: CEBAF Center F326
Contents
Agenda
- Announcements
- Single-track jobs running: Simon, Mark
- Review of minutes from the last meeting: all
- Reconstruction sub-group reports
- Calorimeters
- Tracking
- PID
- Offline Software Review Planning
- Reconstruction Output Format: all
- EventStore
- Action Item Review
- Review of recent repository activity: all
Communication Information
Video Conferencing
- ESNet: 8542553
- EVO:
- Meeting URL: http://evo.caltech.edu/evoNext/koala.jnlp?meeting=ete8eavBvvanaaIiaiIt
- Phone Bridge ID: 11 6471
Slides
Talks can be deposited in the directory /group/halld/www/halldweb1/html/talks/2012-1Q on the JLab CUE. This directory is accessible from the web at https://halldweb1.jlab.org/talks/2012-1Q/ .
Minutes
Present:
- CMU: Will Levine, Curtis Meyer
- FSU: Nathan Sparks
- IU: Ryan Mitchell, Kei Moriya, Matt Shepherd
- JLab: Mark Ito (chair), Simon Taylor, Beni Zihlmann
Announcements
Simon and Mark reported that single-charged-track diagnostic jobs are now running nightly on an ifarm machine at JLab. The success probability is still a bit low (due to Computer Center controls of multiple jobs) and adjustments will have to be made, but some results can be seen at the top-level web page.
Review of minutes from the last meeting
We reviewed the minutes from the previous meeting, from before the collaboration meeting, without significant comment.
Reconstruction sub-group reports
Calorimeters
Will gave a summary of his work thus far characterizing photon reconstruction in 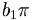 events. See his wiki page for details and plots. He studied the BCAL and FCAL separately. In the BCAL he sees about a factor of three more photons reconstructed than thrown but a simple timing cut eliminates most of the spurious reconstructed photons, leaving the right number and a reasonable energy spectrum. In the FCAL there is a similar multiplication in photons from generated to reconstructed, but timing only removes half of the total (a larger factor is desired). Will is investigating these issues further.
events. See his wiki page for details and plots. He studied the BCAL and FCAL separately. In the BCAL he sees about a factor of three more photons reconstructed than thrown but a simple timing cut eliminates most of the spurious reconstructed photons, leaving the right number and a reasonable energy spectrum. In the FCAL there is a similar multiplication in photons from generated to reconstructed, but timing only removes half of the total (a larger factor is desired). Will is investigating these issues further.
Tracking
Simon told us about his recent change to the tracking code. Simple version [oversimple?]: FDC hits are no longer used by the CDC track factory.
Reconstruction Output Format
We talked about the UConn DST format. Mark (echoing Matt's comment at the last meeting) proposed that we support it as a collaboration and use it as a starting point for a reconstruction output format. It exists, it has been reviewed at some level by the collaboration, and had been designed with compactness in mind.
Matt reiterated his concept that analysis should take place with high-level objects in JANA. As such the DST should contain the minimum amount of information needed to recreate all the necessary objects. Some computation may be required to do this. It is therefore not necessary for there to be a one-to-one correspondence between elements in the DST event structure and the structure of the high-level analysis objects, although that is not excluded where appropriate.
Mark wondered whether the current DST could support this vision as it was not designed with this role in mind. Matt did not see any evidence that it could not. He thought we should focus our design effort on the structure of the analysis objects. If necessary, the DST and the lower-level objects could be reworked to support them; some tweaking and iteration will be necessary.
We agreed to proceed this way along these lines and adopt the UConn DST as an initial serialization format.
We talked briefly about making utilities to make say ROOT trees from DST's. Matt thought rather that it would be better to create the root trees from analysis objects, using the DST's to provide data to create said objects.
EventStore
Matt declined to describe the EventStore system, stating that everything that needed to be said was in the email he sent out. As such we dove directly into discussion.
skims without duplication of events versioning of reconstruction code hooks for skimming events based on various criteria possibility for alternate reconstruction algorithm on previously reconstructed data
do we want to pursue? at what priority?
Matt knows the developers Many users over a number of years Good pedigree
Questions:
how portable is the code base? how easy to add new (our) event formats to the system? random access scheme in particular how much disk space is required to use effectively? when do we need this functionality?
random access needs to be explored 10's of TB level at cleo-c access to large amount of disk space