GlueX Offline Meeting, April 2, 2014
GlueX Offline Software Meeting
Wednesday, April 2, 2014
1:30 pm EDT
JLab: CEBAF Center F326/327
Contents
Agenda
- Announcements
- Review of minutes from the last meeting: all
- Data Challenge Meeting Report, March 28 (Mark)
- REST filesizes and reproducibility (Kei)
{kind=link}
Communication Information
- To join via Polycom room system go to the IP Address: 199.48.152.152 (bjn.vc) and enter the meeting ID: 292649009.
- To join via a Web Browser, go to the page https://bluejeans.com/292649009.
- To join via phone, use one of the following numbers and the Conference ID: 292649009
- US or Canada: +1 408 740 7256 or
- US or Canada: +1 888 240 2560
Slides
Talks can be deposited in the directory /group/halld/www/halldweb/html/talks/2014-2Q on the JLab CUE. This directory is accessible from the web at https://halldweb.jlab.org/talks/2014-2Q/ .
Minutes
Present:
- CMU: Paul Mattione, Curtis Meyer
- IU: Kei Moriya
- JLab: Mark Ito (chair), Sandy Philpott, Dmitry Romanov, Simon Taylor, Beni Zihlmann
- MIT: Justin Stevens
- NU: Sean Dobbs
Review of Minutes from the Last Meeting
We looked over the minutes from March 19. Sean has done some work wrapping HDDM calls for use with Python[?], as part of exploring the use of EventStore.
Data Challenge Meeting Report, March 28
We also looked over these minutes as well. Some of Mark's comments (see below) addressed issues raised last Friday.
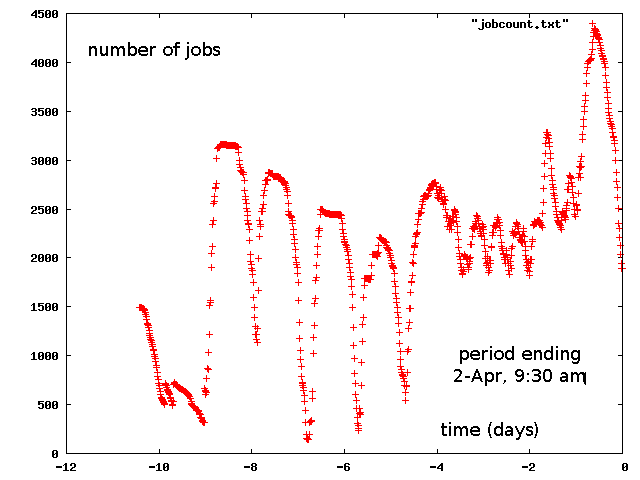
Plot of Running DC2 Jobs as a Function of Time at JLab
Mark showed a plot:

We have borrowed another 1000 cores from the LQCD farm, bringing our share up to about 4000 cores. This last slug came in over the last couple of days.
The large fluctuations are due to the fact that the farm scheduler cannot take into account usage by a user until the end of jobs. At start-up, if jobs take 24 hours to run (as these do), then during that initial period usage from those jobs is assumed to be zero. Also during this period, the user is boosted in priority in order to make up for lack of usage in the recent past. After the jobs complete are done, and all of that usage accounted for, the user appears to be over quota and gets turned off for a while, and so on. This turns out to be completely normal behavior for the system given long-standing parameter settings.
Comments on DC2 Issues
Mark led us through his wiki page, commenting on three topics:
- Monitoring quality of the current data challenge
- We decided that we would by hand look at the monitoring histograms we are producing for each job, for every 1000th job. Simon will do the looking at JLab. Sean will share a script he has written to compare histograms to standards. This should help.
- File transfers in and out of JLab
- Sean thought that that the Globus Online options would not work for pushing files to SRM-capable sites. He thought that the SRM client tools would be sufficient if they could be installed at JLab. He also suggested that we look into raw GridFTP (as Chip Watson has suggested in the past).
- Event Tally Board
- We agreed to maintain a Data Challenge 2 Event Tally Board to keep track of progress.
Returning Nodes to LQCD
We had a brief discussion on how long we should be using the nodes we have borrowed from LQCD. We still have a substantial balance on the amount owed to Physics from the December-March loan to LQCD. Curtis pointed out that we have already hit a 4500 job milestone, exceeded the benchmark of 1250 cores that had been set for us. Mark pointed out that the cores are all doing useful work. The OSG "site" has not come online yet. Given that the OSG contributed 80% of the cycles for the last data challenge it is hard so say where we are now.
We did not come to firm decision but will have to revisit this every few days or so. For now we continue to run with the 4000 total cores.
REST Filesizes and Reproducibility
Kei presented recent studies he has done comparing repeated reconstruction runs on the same smeared event file. See his slides for details. His slides covered:
- Output file sizes
- A bad log file (hdgeant)
- Run info (cpu time, virtual memory)
- File size correlation (mcsmear, iteration to iteration)
- File size correlation (REST, iteration to iteration)
- File size correlation at IU
- hd_dump of factories (comparison of iterations)
- Single different event
- File size correlation with CMU (REST)
We remarked that numerical differences observed are truly in the round-off error regime. We also thought it was odd that identical runs at IU and CMU should differ by as much as 1% in file size. Progress from this point looks difficult given the small differences being reported. Kei will continue his studies.
Next Data Challenge Meeting
We agreed to meet again on Friday to update tallies and discuss schedule.